For fifteen years, finding an influencer meant the same thing: open a database, pick a platform, drag the follower sliders, choose a country, tick a few category boxes, and type a keyword into a bio search. You got back a list. Then you spent the rest of the week scrolling through it by hand, hoping the right creator was in there somewhere.
That model is breaking. The reason is not that the databases got worse — it's that the tools you use everywhere else got better. You ask ChatGPT a question in plain English and it understands you. You expect the same from creator search. “Filter-based discovery,” the term we'll use for the old way, is being replaced by AI that reads what a creator actually posts and matches it to what you actually mean.
AI influencer discovery is the practice of finding creators by describing your intent in natural language, then letting a system match on the meaning of their content, their audience, and their fit with your brand — instead of matching keyword strings against bio text. It's the difference between “creators with ‘coffee’ in their bio” and “micro creators who actually film home-espresso content for an audience that buys gear.”
This piece walks through the whole arc: why filters fail, what AI-native discovery means, how natural-language search works under the hood, why explainable match scoring matters, and the shift already underway where AI agents — not just people — do the searching through an API and the Model Context Protocol. It ends honestly, with the things AI still can't do.
The old way: filter-based search is broken
Legacy influencer databases all work the same way. You start by choosing a platform, then you narrow a population of millions down with structured filters: a follower range, a location dropdown, a category checkbox or two, an engagement-rate floor, maybe a keyword that has to appear in the bio. The result is a sortable table. Your job is to read it.
This breaks in four predictable ways.
- You have to already know what you're looking for. Filters can only express what you can name in advance. If you don't already know that “cottagecore baking” is the niche you want, no checkbox will surface it.
- Bio keywords miss the creators who don't self-describe. A creator who posts daily about budget travel but writes “just a girl with a passport” in her bio is invisible to a keyword filter. The content is right there in every post; the search never looks at it.
- Category buckets are coarse. “Beauty” lumps together a clinical skincare reviewer and a glam makeup artist who share almost no audience. The bucket tells you nothing about what the creator is actually about.
- There's no concept of fit. A filter can confirm a creator has 50K followers in the US. It cannot tell you whether those followers are the people who buy your product, or whether the creator's last ten posts would sit well next to your brand.
The outcome is familiar to anyone who has run a program this way: thousands of technically matching results, an exhausting manual vetting slog, and a quiet certainty that the best long-tail creators — the ones who don't optimize their bios for search — never showed up at all.
What “AI-native” discovery actually means
AI-native discovery flips the input and the matching layer. Instead of translating your need into filters, you state your need in a sentence and the system does the understanding. Three shifts define it.
- Natural-language queries instead of filters. You write a sentence. The system parses the follower range, niche, geography, and behavior out of it — you don't set them by hand.
- Semantic content understanding instead of string matching. The system knows what a creator posts about by reading captions, transcribing videos, and interpreting images — not by checking whether a word appears in a bio.
- Brand-fit scoring with reasons instead of a sortable list. The output is a ranked shortlist where each creator carries a match score and the evidence behind it, so you can trust the ranking instead of re-vetting it.
The two models side by side:
| Dimension | Filter-based discovery | AI-native discovery |
|---|---|---|
| Query input | Dropdowns, sliders, checkboxes, bio keyword | A plain-English sentence describing intent |
| What it matches on | Structured metadata and bio text strings | Meaning of captions, transcripts, images, and audience |
| Vetting effort | High — you read and judge every row | Low — the score and reasons do the first pass |
| Long-tail recall | Poor — misses creators who don't self-describe | Strong — finds creators by what they post |
| Output | A raw, sortable table of matches | A ranked shortlist with fit scores and reasons |
Natural-language search in practice
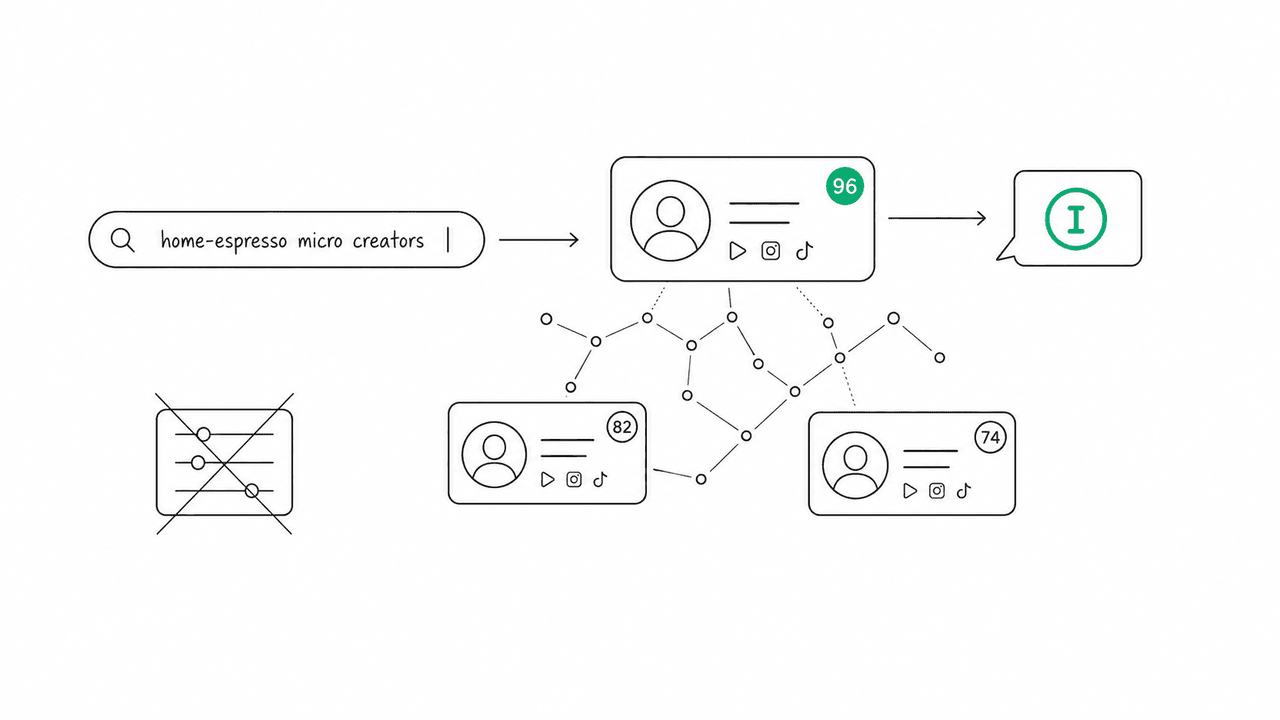
The clearest way to see the difference is to look at a real query. A natural-language creator search engine is built to take a sentence like this and rank creators by brand fit:
“Micro creators in Austin who post about home espresso and already use affiliate codes.”
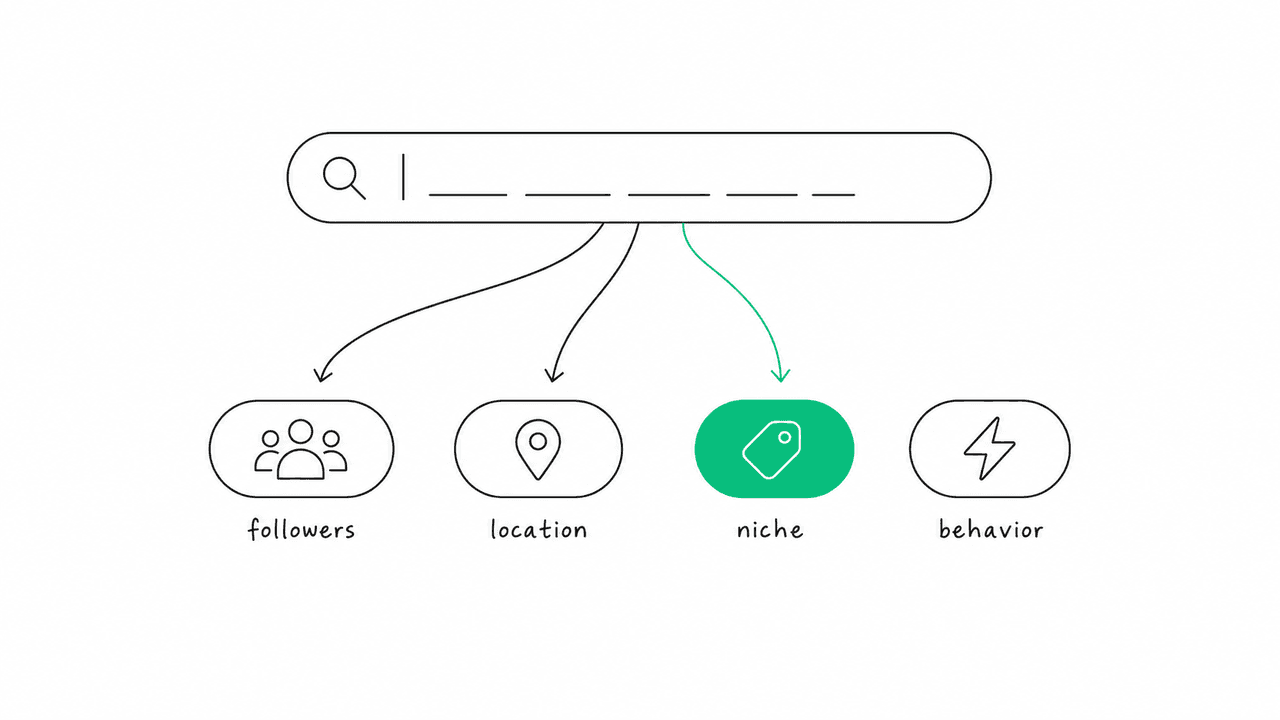
Read what that one sentence encodes. “Micro” is a follower range. “In Austin” is geography. “Post about home espresso” is a content niche far more specific than any “food & drink” category. “Already use affiliate codes” is a behavioral signal that tells you this creator is comfortable with commercial partnerships. A filter UI would need five separate controls for that, and the “home espresso” and “uses affiliate codes” parts have no control at all. Another example: “YouTubers who review budget camping gear for families” bundles platform, content type, price tier, and audience into one line.
Under the hood, lightly, the system does three things:
- It embeds creator content. Captions, video transcripts, and image understanding get converted into embeddings — numerical vectors that place semantically similar content near each other in space. A post about pulling espresso shots and a post about dialing in a grinder land close together even if they share no words.
- It runs vector search. Your query gets embedded the same way, and the system retrieves the creators whose content sits nearest your intent — meaning, not keywords, drives the match.
- It re-ranks by brand intent. A second pass orders the candidates by how well they fit the full intent, including behavioral and audience signals the first retrieval pass treats loosely.
This is exactly how Influship's influencer discovery works: semantic search over creator content, then match scoring with reasons attached. If you want the plain definition of the category, the influencer discovery glossary entry is the short version.
Brand-fit scoring and explainability
A ranked list is only useful if you can trust the ranking. The thing that earns that trust is explainability: AI discovery shouldn't just return a score, it should return the reasons behind it. A useful result looks less like “0.87” and more like this:
{
"creator": "@espresso.at.home.atx",
"match": {
"score": 0.89,
"decision": "good",
"reasons": [
"Posts home-espresso content weekly: grinders, dialing-in, latte art",
"Audience is 71% US, concentrated in Texas",
"Already runs affiliate codes for two gear brands",
"Brand-safety signals clean across last 30 posts"
]
}
}Those reasons are what make a score actionable. You can see why a creator ranked where they did, override the model when you disagree, and skip re-vetting the obvious wins. Explainability also matters for brand safety: a system that can name the content themes and flag the risks is one you can defend to a legal team, not just a black box that spits out a number.
The same engine powers lookalike discovery. Seed it with a creator you already love and it returns semantically similar creators — people whose content and audience resemble your seed. That's a different thing from the “similar accounts” trick most tools ship, which walks the follower graph and surfaces accounts that happen to be followed by the same people. Follower-graph similarity finds proximity; semantic similarity finds creators who actually make the same kind of work.
The agent era: discovery as an API and MCP
Here's the shift most teams haven't priced in yet: humans are no longer the only ones searching. AI agents are. When discovery is exposed as a clean API and over MCP, an agent can find creators, vet them, and build a shortlist on its own — no dashboard, no human dragging sliders.
The Model Context Protocol, introduced by Anthropic in late 2024, is the open standard that makes this work. It lets an AI client inside Claude, Cursor, or your own app call external tools with structured inputs and get structured results back. A discovery API behind an MCP server means an agent can run a natural-language search, read the match scores and reasons, and act on them — the same data a person would use, delivered in a shape a model can reason over.
Influship is built agent-native for exactly this. It ships a hosted MCP server, a developer influencer discovery API, and first-class AI-agent integration, including support for x402 agentic payments so an agent can pay per request without a human in the billing loop. If you're building on this, start with the developer hub and the dedicated guide to influencer marketing for AI agents.
The practical side is well documented. The influencer marketing MCP server explainer covers the protocol end to end; the roundup of the best influencer marketing MCP servers compares the options; and the walkthrough of an automated influencer pipeline in Claude Code runs discovery through outreach as a single agent loop with working code.
What AI discovery still can't do
AI-native discovery is a real upgrade, not magic. Three limits keep the honest version of this story intact.
- It can't replace human judgment on creative fit and negotiation. A model can tell you a creator's content and audience match. It can't tell you whether their voice is the one you want representing your brand, or close a deal at a price you'd sign off on. Taste and negotiation stay human.
- It's bounded by data freshness and coverage. Semantic search is only as good as the content it has indexed. A creator who posted something brand-relevant yesterday won't surface until that content is ingested, and a platform the tool doesn't cover is a blind spot regardless of how good the matching is.
- It doesn't remove the need for fraud checks. A high match score on a creator with a bought audience is a confident wrong answer. You still need fake-follower detection as a separate gate before money moves.
How to evaluate an AI influencer discovery tool
Most tools now claim to be “AI-powered.” The label is meaningless on its own. Run any candidate through this checklist:
- Does it take natural language? Real natural-language search parses a full sentence. A search box that just keyword-matches your text is a filter with a friendlier label.
- Does it understand content, not just bios? Ask whether it indexes captions, transcripts, and images. If it only reads bios and metadata, it can't do semantic matching.
- Does it explain its matches? A score with no reasons is a black box. Look for the evidence behind the ranking.
- Does it offer an API and MCP? If you want agents to do the work, the tool has to be callable by them. A dashboard-only product can't be automated.
- How is the data coverage and freshness? Ask how many creators, which platforms, and how recently the content was indexed.
It's worth running your current tool through the same questions. The Influship comparison hub stacks the major platforms against these criteria, and the head-to-head with HypeAuditor is a good place to see how a database-first tool and an AI-native one diverge on exactly these points.
Frequently asked questions
What is AI influencer discovery?
AI influencer discovery is the practice of finding creators by describing your intent in natural language and letting a system match on the meaning of their content, audience, and brand fit — rather than matching keyword strings against bio text the way legacy filter databases do. It typically uses embeddings and vector search over captions, transcripts, and images, then returns a ranked shortlist with match scores and reasons.
How is AI search different from filter-based databases?
Filter-based databases take structured inputs — follower range, location, category, bio keyword — and return a raw table you have to vet by hand. AI search takes a plain-English sentence, understands what creators actually post about, and returns a ranked shortlist with explanations. The big practical wins are far less manual vetting and much better recall on long-tail creators who don't optimize their bios for search.
Can AI find influencers automatically?
Yes. When discovery is exposed as an API and over the Model Context Protocol, an AI agent can run searches, read the match scores and reasons, and build a shortlist on its own. Influship ships an MCP server and developer API for exactly this, so an agent in Claude, Cursor, or a custom app can do discovery without a human driving a dashboard.
Does AI discovery replace manual vetting?
No — it augments it. AI handles the heavy first pass: surfacing the right creators, scoring fit, and flagging risks. Humans still own creative judgment, negotiation, and the final call, and you still need a separate fake-follower check before committing budget. The point is to spend your judgment on the ten creators worth judging, not the thousand the old way made you read.
Where this is headed
The arc is clear: filters gave way to AI-native search, and AI-native search is giving way to agents that run discovery themselves. Each step moves the manual work off your plate and the judgment up the stack. Filters made you do the system's job; AI does the matching; agents do the running. What stays yours is taste.
Influship is the platform built for that arc — semantic discovery, explainable match scoring, lookalikes, and the API and MCP layer that lets agents do the searching. Start with AI influencer discovery, or request a demo to see it run against your next campaign.
Sources and further reading
- Anthropic, “Introducing the Model Context Protocol” (2024) — the open standard for connecting AI assistants to external tools and data.
- Model Context Protocol, official documentation and specification.
- Wikipedia, “Word embedding” — background on vector representations of meaning that power semantic search.
- Influencer Marketing Hub, “Influencer Marketing Benchmark Report” — annual industry data on AI adoption and discovery practices.
- Influship product capabilities: semantic creator search, match scoring with reasons, and lookalike discovery (features/influencer-discovery, developers/api).