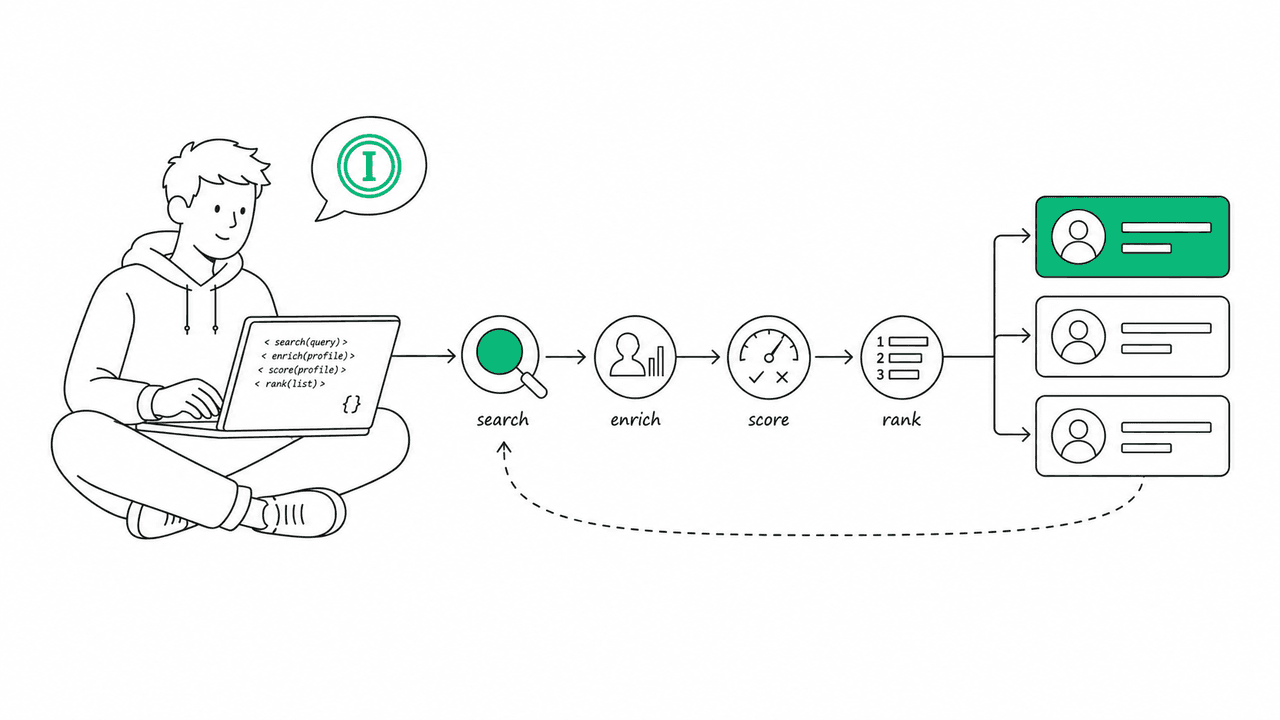
Almost every “how to find influencers” article ends at the dashboard. Open a tool, type a niche, scroll a list. That is fine until you want discovery to be a step inside your own software — a script that runs nightly, a Slack command, an internal app your marketing team uses, or a loop an AI agent drives on its own. For that, you do not need a dashboard. You need an API and a few hundred lines of code.
This is the tutorial. By the end you will have a working tool that takes a plain-English brief like “vegan skincare micro-influencers in the US, 20–80k followers, high engagement” and returns a ranked, scored shortlist with enrichment — names, live metrics, AI summaries, and a good/neutral/avoid call on each creator against your brief. All of it in TypeScript, all of it copy-pasteable.
The pipeline is four moves: search turns the brief into candidates, enrich pulls live metrics and AI context, score rates each candidate against the brief, and rank sorts the survivors and drops the ones flagged to avoid. There is an optional fifth move — lookalike expansion — when you want to widen the pool from your best result.
I am using the Influship creator API for this because it does the heavy lifting (semantic search, profile data, and AI match scoring) behind one SDK, so the code stays short. If you want the conceptual version of what each call does, the influencer discovery glossary entry and the discovery feature page cover it. This post is the build.
What you'll build
A small command-line tool (it ports cleanly to a Next.js route or a serverless function) that does this, in order:
- Query. You pass a natural-language brief and a few hard constraints (follower band, minimum engagement, platform).
- Search. The brief becomes a ranked list of candidate creators, each with a relevance score and reasons.
- Enrich. For the shortlist, you fetch live metrics and an AI summary, content themes, and brand-alignment tags.
- Score. Each enriched candidate is matched against the brief and returns a good / neutral / avoid decision plus evidence.
- Rank. You sort by score, drop the “avoid” calls, and print a clean table.
Prerequisites: Node 18+ and TypeScript, an Influship API key from developers.influship.com (sign up, create a key, you get trial credits), and five minutes. That is the entire setup.
Architecture: why separate discovery from scoring
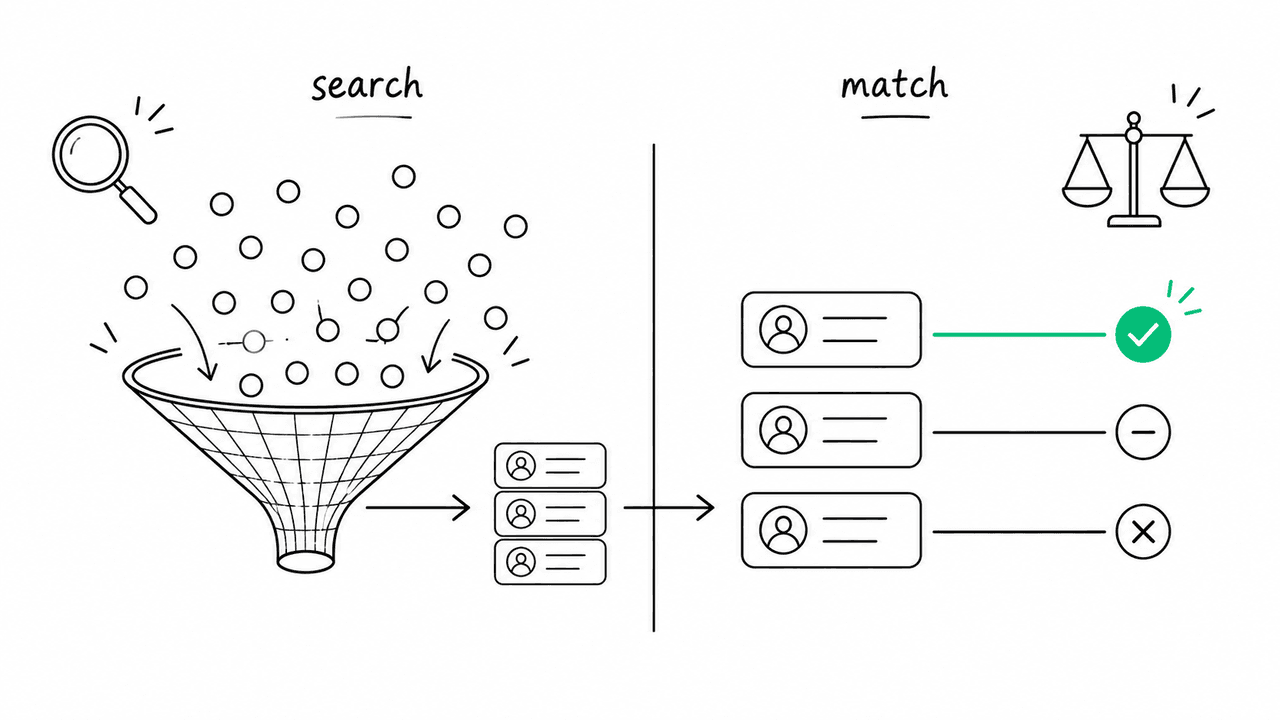
The instinct is to do everything in one call. Resist it. The tool uses three distinct endpoints, and the separation is the whole point:
search.create— discovery. Broad, cheap, fast. Cast a wide net from the brief and get back a ranked candidate pool.profiles.get/creators.retrieve— enrichment. Pull live metrics and AI-synthesized context for the candidates that survived the first cut.creators.match— scoring. A deliberate, evidence-based judgement of each candidate against your specific campaign.
Search ranks for relevance to a query. Match scores for fit to a campaign. Those are different questions, and conflating them is the most common reason home-grown discovery tools return plausible-looking garbage. A creator can be highly relevant to “vegan skincare” and still be the wrong fit for your brand because their last ten posts were paid promos for a competitor. You only learn that in the scoring step. Keeping the two separate also lets you cache search results (they are cheap and stable) and only spend the pricier match credits on a vetted shortlist.
Step 1 — Set up the client
Install the SDK and initialise the client. Never hard-code the key — read it from the environment so it never lands in git.
// client.ts
import Influship from 'influship';
if (!process.env.INFLUSHIP_API_KEY) {
throw new Error('Set INFLUSHIP_API_KEY in your environment');
}
export const client = new Influship({
apiKey: process.env.INFLUSHIP_API_KEY,
});Put the key in a .env file (and add it to .gitignore): INFLUSHIP_API_KEY=sk_live_.... Get the key from developers.influship.com. That is the whole client. Every other step imports this client.
Step 2 — Run a natural-language search
This is where the brief becomes candidates. search.create is the same engine behind Influship's natural-language influencer search, and it takes a natural-language query and optional hard filters. The query carries the intent (“vegan skincare,” “US audience”); the filters carry the non-negotiables (follower band, minimum engagement). Note that engagement rate is passed in decimal units — 2% is 0.02, not 2.
// search.ts
import { client } from './client';
export async function findCandidates(brief: string) {
const res = await client.search.create({
query: brief,
limit: 40,
platforms: ['instagram'],
creator_kinds: ['INFLUENCER'],
filters: {
followers: { min: 20_000, max: 80_000 },
feed_engagement_rate: { min: 0.03 }, // 3%+
},
});
return res.data.map((row) => ({
id: row.creator.id,
name: row.creator.name,
username: row.primary_profile?.username ?? null,
relevance: row.match.score, // 0-1, search relevance
reasons: row.match.reasons, // why it matched
}));
}A trimmed sample of what comes back from the raw call:
{
"search_id": "srch_a1b2c3",
"total": 128,
"has_more": true,
"next_cursor": "eyJvZmZzZXQiOjQwfQ==",
"data": [
{
"creator": { "id": "cr_9f3...", "name": "Maya Greenleaf" },
"match": {
"score": 0.91,
"reasons": ["Posts vegan skincare routines", "US-based audience"]
},
"primary_profile": {
"username": "mayagreenleaf",
"followers": 47200,
"is_verified": false
}
}
]
}Two fields matter for the rest of the tool. The search_id lets you paginate the same result set for free with GET /v1/search/{id} instead of paying for a fresh search. And next_cursor is how you walk deeper into the list when has_more is true (more on that in Step 3). Forty candidates is plenty for a first pass — you will cut this hard in scoring.
Step 3 — Enrich the shortlist
Search gives you names and a relevance score. To judge fit you need real context. There are two enrichment calls, and you use them for different things:
profiles.get(username, { platform })— fast, cached live metrics: followers, engagement rate, average likes, posting cadence. Cheap (0.1 credits). Use it on the whole shortlist.creators.retrieve(id, { include: ['profiles'] })— the deep one: an AI summary, content themes, brand-alignment tags, audience demographics, and every linked profile. Use it only on the candidates you are serious about.
// enrich.ts
import { client } from './client';
export async function enrich(candidate: { id: string; username: string | null }) {
// Deep context for scoring + display
const full = await client.creators.retrieve(candidate.id, {
include: ['profiles'],
});
// Live cached metrics (skip if username is missing)
const metrics = candidate.username
? await client.profiles.get(candidate.username, { platform: 'instagram' })
: null;
return {
id: candidate.id,
name: full.data.name,
summary: full.data.ai_summary,
themes: full.data.content_themes, // ['skincare', 'vegan', ...]
brandAlignment: full.data.brand_alignment,
followers: metrics?.data.metrics.followers ?? null,
engagementRate: metrics?.data.metrics.engagement_rate ?? null,
postsPerWeek: metrics?.data.metrics.posts_per_week ?? null,
};
}If your initial 40 candidates are not enough — say a tight niche where you want every match — page through the full result set with the cursor. Use the free search_id pagination so you do not pay twice:
// paginate.ts — walk the whole result set for free with search_id
import { client } from './client';
export async function allResults(searchId: string) {
const out: { id: string; name: string; relevance: number }[] = [];
// search.retrieve auto-pages via next_cursor under the hood
for await (const row of client.search.retrieve(searchId)) {
out.push({
id: row.creator.id,
name: row.creator.name,
relevance: row.match.score,
});
}
return out;
}Run enrichment with bounded concurrency (a Promise.all over batches of 5–10), not one giant parallel burst — you will hit rate limits otherwise. We come back to that in Step 5.
Step 4 — Score against the brief
Now the judgement call. creators.match takes your candidates and your campaign intent, then returns a fit score (0–1), a decision (good/neutral/avoid), and structured reasons with evidence. You can pass up to 100 creators in one call, so the whole shortlist goes in a single request.
// score.ts
import { client } from './client';
export async function scoreShortlist(
creatorIds: string[],
brief: string,
) {
const res = await client.creators.match({
creators: creatorIds.map((id) => ({ creator_id: id })),
intent: {
query: brief,
context:
'Indie vegan skincare brand. Cruelty-free, clean-ingredient positioning. ' +
'Avoid creators who recently promoted competitors or non-vegan beauty.',
},
});
return res.data.map((row) => ({
id: row.creator.id,
name: row.creator.name,
fit: row.match.score, // 0-1, campaign fit
decision: row.match.decision, // 'good' | 'neutral' | 'avoid'
reasons: row.match.reasons.map((r) => r.text),
}));
}The context field is doing real work here. The query says what you want; the context says what disqualifies a creator. That is what catches the creator who is topically perfect but just ran a paid post for a competitor — they come back as avoid with a reason that cites the post. This is the step a dashboard-only workflow cannot give you at scale.
Step 5 — Rank and display results
The last move ties it together: search, enrich, score, then sort and filter. Drop everything flagged avoid, sort the rest by fit, and print.
// index.ts — the whole tool
import { findCandidates } from './search';
import { enrich } from './enrich';
import { scoreShortlist } from './score';
const BRIEF =
'vegan skincare micro-influencers in the US, 20-80k followers, high engagement';
// Small concurrency helper so we don't hammer the rate limit
async function mapLimit<T, R>(items: T[], limit: number, fn: (x: T) => Promise<R>) {
const out: R[] = [];
for (let i = 0; i < items.length; i += limit) {
out.push(...(await Promise.all(items.slice(i, i + limit).map(fn))));
}
return out;
}
async function main() {
const candidates = await findCandidates(BRIEF); // Step 2
const enriched = await mapLimit(candidates, 5, enrich); // Step 3, batches of 5
const scored = await scoreShortlist(candidates.map((c) => c.id), BRIEF); // Step 4
const byId = new Map(enriched.map((e) => [e.id, e]));
const ranked = scored
.filter((s) => s.decision !== 'avoid') // drop the no-gos
.sort((a, b) => b.fit - a.fit) // best fit first
.map((s) => {
const e = byId.get(s.id);
return {
name: s.name,
fit: Math.round(s.fit * 100),
followers: e?.followers ?? '—',
engagement: e?.engagementRate ?? '—',
decision: s.decision,
why: s.reasons[0] ?? '',
};
});
console.table(ranked);
}
main().catch(console.error);What that prints, roughly:
┌─────────┬──────────────────┬─────┬───────────┬────────────┬──────────┐
│ (index) │ name │ fit │ followers │ engagement │ decision │
├─────────┼──────────────────┼─────┼───────────┼────────────┼──────────┤
│ 0 │ 'Maya Greenleaf' │ 91 │ 47200 │ 0.052 │ 'good' │
│ 1 │ 'Jules Okafor' │ 88 │ 31800 │ 0.061 │ 'good' │
│ 2 │ 'Priya Anand' │ 74 │ 68400 │ 0.038 │ 'neutral'│
└─────────┴──────────────────┴─────┴───────────┴────────────┴──────────┘That is a working discovery tool in well under two hundred lines. A few production notes before you ship it:
- Rate limits. Keep enrichment concurrency bounded (the
mapLimithelper above). On a 429, back off and retry — see Step on production below. - Cache enrichment. Profile metrics and creator details change slowly. Cache them by creator ID for 24–48 hours and you cut both cost and latency dramatically.
- Idempotency. Searches are deterministic enough to dedupe on the brief string. Store the
search_idand reuse it for free pagination instead of re-searching.
Step 6 — Add lookalike expansion (optional)
Sometimes the brief is too narrow and you want more like your best result. Feed a top creator in as a seed and creators.lookalike returns similar creators — same niche, comparable audience, matching posting style. It is a paginated iterator, so you can pull as deep as you need.
// lookalike.ts
import { client } from './client';
export async function expandFrom(seedCreatorId: string, max = 20) {
const found: { name: string; similarity: number; traits: string[] }[] = [];
for await (const item of client.creators.lookalike({
seeds: [{ creator_id: seedCreatorId, weight: 1 }],
filters: { followers: { min: 20_000, max: 80_000 } },
limit: max,
})) {
found.push({
name: item.creator.name,
similarity: item.similarity.score,
traits: item.similarity.shared_traits,
});
if (found.length >= max) break;
}
return found;
}Run the lookalikes back through Step 3 and Step 4 — enrich, then score against the brief — and they slot straight into the same ranked list. That is the whole loop: discover, expand, enrich, score, rank.
Going to production
The script above is the skeleton. To run it as part of real software, add four things:
Retries and backoff. Wrap each call so a 429 or a transient 5xx retries with exponential backoff (e.g. 1s, 2s, 4s, jittered) before giving up. The SDK surfaces HTTP status on errors, so you can branch on it.
Credit budgeting. Costs are predictable, so budget per run. Search is 25 credits base plus 2 per result; creators.retrieve is 0.1 credits; profiles.get is cheap; creators.match is 1 credit per creator scored; lookalike is 1.5 credits per creator returned. A 40-candidate run that enriches and scores the lot costs roughly a dollar or two. Cap the candidate count and the lookalike depth and you control spend exactly. Current per-credit pricing lives in the API docs.
Storage. Persist ranked results in your own database so you are not re-running discovery to look at last week's shortlist. Once you store outreach status alongside the creator record, you have effectively built a lightweight influencer CRM. The discovery tool becomes the front of a longer pipeline.
Hand it to an agent. Every step here is a deterministic function with typed inputs and outputs, which is exactly what an AI agent needs to run the loop unattended. Instead of a hard-coded brief, let the agent decide when to widen the pool with lookalikes, when a shortlist is good enough, and when to escalate to a human. We wrote two companion guides for that path: automating the next stage in automate influencer outreach with the API, and the connector layer in the best influencer marketing MCP servers. The full developer reference for agent workflows is on the AI agents page.
If you want the broader context on what the creator API can do beyond discovery — profiles, matching, the full endpoint surface — start with the influencer API overview and the influencer marketing API guide. For the Instagram-specific search angle, see the Instagram influencer search API post.
FAQ
What data do I need to build a discovery tool?
Three kinds: a way to search creators by intent (not just exact keywords), profile data (followers, engagement, posting cadence), and fit signals (content themes, brand alignment, recent post context). The Influship API bundles all three behind search.create, profiles.get / creators.retrieve, and creators.match, so you do not assemble it from separate sources. You bring the brief; the API brings the data.
Can I build this without scraping?
Yes — that is the point of using an API. Scraping Instagram or YouTube yourself means fighting bot detection, rotating proxies, and maintaining brittle selectors that break on every UI change, plus the legal exposure that comes with it. The calls in this tutorial hit a maintained, documented API. You write business logic, not scrapers.
How much does the API cost to run this?
A single full run — search 40 candidates, enrich them, score them — lands around one to two dollars at current credit pricing (search is 25 credits plus 2 per result; creators.match is 1 credit per creator; creators.retrieve is 0.1). With caching on enrichment and free search_id pagination, repeat runs cost far less. New keys come with trial credits, so the first builds are free. Live numbers are in the docs.
Can an AI agent run this loop?
Yes, and it is the natural next step. Each function here is typed and deterministic, so an agent can chain them, decide when to expand with lookalikes, and gate outreach behind a human. The same operations are exposed as MCP tools, so an assistant in Claude Code or Cursor can call them directly. See the AI agents guide and the MCP server roundup for the agent path.
Sources and further reading
- Influship SDK reference —
search.create,profiles.get,creators.retrieve,creators.match, andcreators.lookalikeparameters, response shapes, and per-call credit pricing. docs.influship.com. - Influship developer portal — API-key acquisition and trial credits. developers.influship.com.
- Influship influencer API overview — influship.com/developers/api.